
Regular Expression Translator
Another class I am taking this semester (except Real-Time Systems which I blogged about) is Formal Language Theory. It is very theoretical course. Most of the time is spend on formal proofs. Fortunately, one programming assignment was very fun.
The goal was to implement the program, which checks if one regular expression is subset of another. Thus, the input is two regular expressions.
 The program use basic regular expressions notation and supports following operators:
The program use basic regular expressions notation and supports following operators:
- + (union)
- * (Kleene closure)
- ε (Epsilon, empty expression)
- 0,1,2 (literals)
To solve the problem, I had to take advantage of finite automatas (ε-NFA and DFA) in following order:
- Parse regular expressions E1 and E2
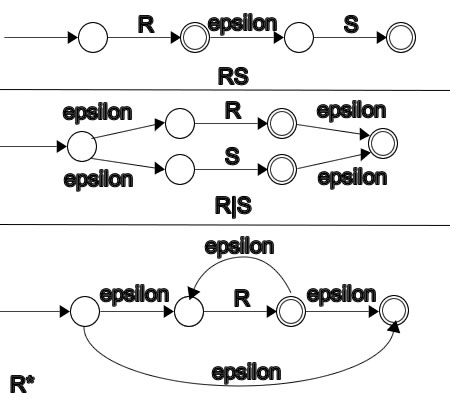
- Create ε-NFAs N1 and N2 using Visitor pattern and transition described here
- Convert ε-NFAs N1 and N2 to DFAs D1 and D2 based on this
- Create D'I DFA, which is intersection of D1 and D2 DFAs generated in step 3
Implementation details
Tools/Technologies:
- Eclipse
- Scala
- Java
- ANTLRWorks 2
- Scala JUnit tests
I took advantage of ANTLR for parsing. I want to learn Scala and I am using it for every programming assignment in this semester if possible. ANTLRWorks 2 does not support Scala (it does not generate parser/lexer/visitor in Scala). However, ANTLRWorks 2 generates Java and interoperability between Scala and Java is easy. I decided to try it!
Scala is a main language in which this application was developed. ANTLRWorks 2 was used for parsing regular expression. The new version (v.2) generates Visitor class, which enables iterating through AST (Abstract Syntax Tree) nodes and perform appropriate actions. As I mentioned, ANTLRWorks 2 does not generate Scala code yet. Thus the generated parser and Visitor is in Java language.
During the intersection of DFAs creation, there is an exception thrown in 2 cases:
- There exists some node of newly created D’I DFA, which is sum of D1 final node and D2 not final node
- Some transition, which exists in D1 leads to dead node in D2
Exception contains string, which is accepted by L(E1), but not by L(E2). Then, this string is returned as a result of execution. If no exception was thrown, it means, every final state of D1 is also final state of D2. That means L(E1) ∈ L(E2) and 'true' is returned.
Running program
The main program is Main.scala. You can find there String variables defined with sample Regular Expressions. The easiest way is to replace them (if you want to test different ones). You can also read input from the console (by commenting and uncommenting appropriate lines).
Empty regular exception cause Exception throw.
There is also set of unit tests to test some regular expressions. You are more than welcome to add new Unit tests if you want to.
Input
Every closure has to have parenthesis: (exp)*
Union also require parenthesis and multiple unions are allowed: (exp1+exp2+exp3)
Sample inputs:
- (0+1+2)*
- ((0(0+2)*+1)*+2)
- ((0(0+2)*+1)*+2+12+(00+21)*+0000110102)
Details about accepted input can be found in ANTLR grammar file.
Summary
In this assignment I was able to reuse my knowledge about compilers, learnt last semester in Compilers course I had. Additionally I had to implement automata representation and apply recursion to accomplish required tasks.
It is very simple translator. Handle only basic regular expressions and small language (only 0,1,2 literals allowed). However, the goal was to practice and understand how Regular Expressions work internally.
You can check the code of my translator on github: RegExpTranslator.